|
“τΤΒΙΛ≥Χ ΠΟφΝΌΒΡΧτ’Ϋ «…ηΦΤ…η±ΗΘ§ΧαΙ©ΗϋΚΟΒΡ“τΤΒ±Θ’φΕ»Θ§÷ß≥÷ΗϋΕύ“τΤΒΆ®ΒάΘ§¥ΠάμΗϋΗΏΒΡ≤…―υ¬ ΚΆΈΜ…νΕ»Θ§Ά§ ±±Θ≥÷Ϋτ’≈ΒΡ Β ±¥Πάμ‘ΛΥψΓΘ
‘Ύ–μΕύ“τΤΒ”Π”Ο÷–Θ§œΒΆ≥–‘ΡήΒΡ÷ς“ΣΤΩΨ± «“τΤΒ ΐΨίΒΡΗΏ–ß“ΤΕ·ΓΘΕύΡξά¥Θ§ ΐΉ÷–≈Κ≈¥ΠάμΤς (DSP) ΦήΙΙ“ΐ»κΝΥΗς÷÷¥¥–¬Θ§¥” DSP ΡΎΚΥ–Ε‘ΊΝΥ–μΕύ I/O Μρ ΐΨί“ΤΕ·»ΈΈώΘ§ ΙΤδΡήΙΜΉ®ΉΔ”Ύ–≈Κ≈¥Πάμ»ΈΈώΓΘ
÷±Ϋ”ΡΎ¥φΖΟΈ (DMA) “ΐ«φ «Β±Ϋώ¥σΕύ ΐΗΏ–‘Ρή DSP ΒΡΙΊΦϋΉιΦΰΓΘDSP Ω…“‘≈δ÷Ο DMA “ΐ«φά¥ΖΟΈ Τ§…œΚΆΤ§ΆβΉ ‘¥Θ§≤Δ¥ΌΫχΥϋΟ«÷°ΦδΒΡ¥Ϊ δΘ§Εχ≤Μ±Ίœ‘ ΫΖΟΈ ¥φ¥ΔΤςΜρΆβ…ηΓΘ’β–© DMA ¥Ϊ δΩ…“‘”κΙΊΦϋ DSP ΡΎΚΥ¥Πάμ≤Δ––÷¥––Θ§“‘ΜώΒΟ–‘ΡήΓΘ
±ξΉΦ DMA “ΐ«φΖ«≥Θ Κœ¥ΪΆ≥ΒΡ“ΜΈ§ΚΆΕΰΈ§ΥψΖ®¥ΠάμΘ§άΐ»γΩιΗ¥÷ΤΚΆΜυ±Ψ ΐΨί≈≈–ρΓΘΒΪ «Θ§–μΕύ“τΤΒΥψΖ®–η“ΣΗϋΗ¥‘”ΒΡ ΐΨί¥Ϊ δΓΘ―”≥ΌœΏΨΆ «“ΜΗωάΐΉ”Θ§Υϋ”…«Α“ΜΗω ±ΦδΒψΒΡ“τΤΒ―υ±ΨΉι≥…Θ§”Ο”Ύ¥¥Ϋ®Υυ–ηΒΡ“τΤΒ–ßΙϊΘ®άΐ»γΜΊ…υΘ©ΓΘ¥ΪΆ≥ΒΡ DMA –‘ΡήΕ‘”ΎΙήάμ―”≥ΌœΏά¥ΥΒ≤Δ≤Μ «ΒΡΘ§–η“ΣΕ‘ DMA ΦήΙΙΫχ––¥¥–¬Θ§“‘”––ßΒΊ¥ΠάμΥυ–ηΒΡ“τΤΒΥψΖ®ΓΘ
«Ζώ–η“ΣDMAΦ”ΥΌΘΩ
’βΗωΈ ΧβΒΡ¥πΑΗ «ΩœΕ®ΒΡΘ§‘≠“ρ”–ΝΫΗωΓΘ Ήœ»Θ§–μΕύΗΏ–‘Ρή DSP “ΐ«φ÷–ΒΡ DMA Ά®Βά ΐΝΩœό÷ΤΝΥ (pro) “τΤΒ”Π”ΟΓΘΤδ¥ΈΘ§”…”ΎΕ‘ΗΏ÷ ΝΩ“τΤΒΒΡ–η«σΘ§“τΤΒ”Π”Ο÷–ΒΡ¥ΪΆ≥DMAΆ®≥Θ–η“ΣΗϋΕύΒΡCPU≤Έ”κ

ΆΦ1ΓΘ“τΤΒ”Π”ΟΩρΆΦ
…œΟφΒΡΩρΆΦΟη ωΝΥΒδ–Ά“τΤΒ”Π”Ο÷–ΒΡ ΐΨίΝςΓΘΟΩΗω–ßΙϊΜώ»Γ«Α“ΜΗω–ßΙϊΒΡ δ≥ωΘ§¥Πάμ ΐΨίΘ§≤ΔΫΪΤδ δ≥ωΉΣΖΔΒΫ ΐΨί¥ΠάμΝ¥÷–ΒΡœ¬“ΜΗω–ßΙϊΘ®άΐ»γΘ§Phaser –ßΙϊΒΡ δ≥ω±Μ δ»κΒΫ Delay –ßΙϊΘ§Delay –ßΙϊΒΡ δ≥ω±ΜΖΔΥΆΒΫΜλœλΘ© ΓΘ
…œΆΦΥυ ΨΒΡ ΐΉ÷“τΤΒ–ßΙϊ“άάΒ”Ύ―”≥ΌœΏά¥ Βœ÷ΓΘ‘ΎΟη ωΆξ’ϊΒΡ–ßΙϊœΒΆ≥ ±Θ§–η“ΣΕύΗω―”≥ΌœΏΓΘΗΡ±δ…ηΦΤ÷– Ι”ΟΒΡ―”≥Ό≥ΛΕ»ΜαΗΡ±δ“τΤΒ–ßΙϊΒΡ÷ ΝΩΓΘ
―”≥ΌœΏ «œΏ–‘ ±≤Μ±δœΒΆ≥Θ§Τδ δ≥ω–≈Κ≈ «―”≥ΌΝΥ x Ηω―υ±ΨΒΡ δ»κ–≈Κ≈ΒΡΗ±±ΨΓΘ‘Ύ DSP …œ Βœ÷―”≥ΌœΏΒΡ”––ßΖΫΖ® « Ι”Ο―≠ΜΖΜΚ≥εΤςΓΘ―≠ΜΖΜΚ≥ε«χ¥φ¥Δ‘ΎœΏ–‘¥φ¥ΔΤςΒΡΉ®”Ο≤ΩΖ÷÷–ΘΜΒ±ΜΚ≥ε«χ±ΜΧν¬ζ ±Θ§–¬ΒΡ ΐΨί±Μ–¥»κΘ§¥”ΜΚ≥ε«χΒΡΩΣΆΖΩΣ ΦΓΘ
―≠ΜΖΜΚ≥ε«χ ΐΨί”…“ΜΗωΫχ≥Χ–¥»κΘ§”…Νμ“ΜΗωΫχ≥ΧΕΝ»ΓΘ§’β–η“ΣΒΞΕάΒΡΕΝ–¥÷Η’κΓΘΕΝ–¥÷Η’κ≤Μ‘ –μΫΜ≤φΘ§’β―υΈ¥ΕΝ ΐΨίΨΆ≤ΜΜα±Μ–¬ ΐΨίΗ≤Η«ΓΘ―≠ΜΖΜΚ≥ε«χΒΡ¥σ–Γ”…–ßΙϊΥυ–ηΒΡ―”≥ΌΨωΕ®ΓΘ‘Ύ±ΨΈΡ÷–Θ§œ»Ϋχœ»≥ω (FIFO) ΚΆ―≠ΜΖΜΚ≥ε«χΟϊ≥ΤΩ…“‘ΜΞΜΜ Ι”ΟΓΘ
Β± Ι”Ο¥ΪΆ≥ΒΡ DMA “ΐ«φ‘ΎΜυ”Ύ―”≥ΌΒΡ“τΤΒ–ßΙϊ÷–“ΤΕ· ΐΨί ±Θ§ΜαΈΣ–≈Κ≈¥ΠάμΝ¥÷–ΒΡΟΩΗω–ßΙϊΖ÷≈δ“ΜΗωΒΞΕάΒΡ―≠ΜΖΜΚ≥ε«χΓΘάΓΥΆΒΫΧΊΕ®“τΤΒ–ßΙϊΒΡ δ»κ ΐΨί¥φ¥Δ‘ΎΖ÷≈δΗχΗΟ–ßΙϊΒΡ―≠ΜΖΜΚ≥ε«χ÷–ΓΘœ¬ΟφΒΡΩρΆΦœ‘ ΨΝΥΗϋœξœΗΒΡ ΐΨίΝςΓΘ‘Ύœ¬ΟφΆΦ 2 ΒΡΩρΆΦ÷–Θ§―≠ΜΖΜΚ≥ε«χ”…ΜΖ±μ ΨΓΘ Ι”Ο―≠ΜΖΜΚ≥ε«χΒΡΜΖ–Έ±μ ΨΘ§“ρΈΣΥϋœ‘ ΨΖ÷≈δΗχ―≠ΜΖΜΚ≥ε«χΒΡœΏ–‘ΒΊ÷ΖΩ’ΦδΒΡΑϋΉΑΓΘΒ±÷Η’κΆ®Ιΐ―≠ΜΖΜΚ≥ε«χ«ΑΫχ ±Θ§ΒΊ÷ΖΫΪ‘ωΦ”Θ§÷±ΒΫ”ωΒΫΜΊ»ΤΧθΦΰΘ§ΒΦ÷¬÷Η’κ÷Ί÷ΟΒΫΡΎ¥φΒΊ÷ΖΜρ―≠ΜΖΜΚ≥ε«χΒΡΤπ ΦΒψΓΘ
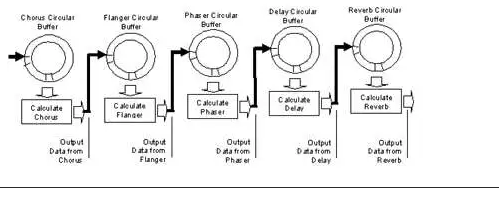
ΆΦ2. Ι”Ο¥ΪΆ≥DMA“ΐ«φ ±ΒΡPro“τΤΒ”Π”Ο ΐΨίΝςΩρΆΦ
ΈΣΝΥ≤ζ…ζ≤ΜΆ§ΒΡ―”≥ΌΘ§DMA ±Ί–κ¥”―”≥ΌœΏΡΎΒΡ≤ΜΆ§ΈΜ÷ΟΦλΥς―”≥Ό ΐΨίΓΘ»γΙϊ Ι”ΟΩι¥ΠάμΘ§‘ρΜαΦλΥς“ΜΉι ΐΨίΕχ≤Μ «Ϋω“ΜΗω―υ±ΨΓΘ
¥ΪΆ≥ΒΡ DMA “ΐ«φΆ®≥Θ‘ –μ≥Χ–ρ‘±÷ΗΕ®ΦΗΗωΆξ’ϊΟη ωΥυ–η¥Ϊ δΒΡ≤Έ ΐΓΘΆ®≥ΘΘ§’β–©≤Έ ΐ «‘¥ΒΊ÷ΖΓΔΡΩ±ξΒΊ÷ΖΓΔ‘¥ΚΆΡΩ±ξΒΡΥς“ΐ“‘ΦΑ¥Ϊ δΦΤ ΐΓΘΟΩ¥Έ DMA ¥Ϊ δΫΪ–η“Σ“ΜΗωΒδ–Ά DMA ΉήΧεΙΠΡήΒΡΆ®ΒάΓΘ
‘Ύ…œΟφΒΡΩρΆΦ÷–Θ§”–ΈεΗω―≠ΜΖΜΚ≥ε«χΓΘ¥ΪΆ≥ΒΡ DMA “ΐ«φ±Ί–κΨ≠Ιΐ±ύ≥Χ≤≈ΡήΫΪ ΐΨί“Τ»κΚΆ“Τ≥ωΟΩΗωΜΚ≥ε«χΓΘ‘Ύ…œΟφΥυ ΨΒΡ”Π”Ο÷–Θ§¥Πάμ“ΜΗω ΐΨίΩι÷Ν…Ό–η“Σ 11 ¥Έ DMA ¥Ϊ δΓΘ
’β «Υυ–ηΒΡ DMA ¥Ϊ δΒΡ ΐΝΩΘ§ΦΌ…η¥”ΟΩΗω―≠ΜΖΜΚ≥ε«χ÷–÷ΜΦλΥςΟΩΗω–ßΙϊΒΡ“ΜΗω―”≥ΌΓΘ‘ΎΒδ–Ά”Π”Ο÷–Θ§ΟΩΗω ΐΨίΩιΒΡ DMA ¥Ϊ δ ΐΝΩΜαΗΏΒΟΕύΓΘάΐ»γΘ§Μλœλ–ßΙϊΒΡ Βœ÷Ήή «–η“Σά¥Ή‘Τδ―≠ΜΖΜΚ≥ε«χΒΡΕύΗω―”≥ΌΓΘ
ΥφΉ≈ Βœ÷ΒΡ“τΤΒ–ßΙϊ ΐΝΩΒΡ‘ωΦ”Θ§Υυ–ηΒΡ¥ΪΆ≥ DMA ¥Ϊ δ ΐΝΩ“≤Μα‘ωΦ”ΓΘ“ρ¥ΥΘ§œΒΆ≥÷–Ω…”ΟΒΡ¥ΪΆ≥ DMA Ά®ΒάΒΡ ΐΝΩΜαœό÷ΤΩ… Βœ÷ΒΡ“τΤΒ–ßΙϊΒΡ ΐΝΩΓΘ
¥ΪΆ≥ DMA ‘Ύ“τΤΒ”Π”Ο÷–ΒΡΨ÷œό–‘
±ξΉΦ DMA “ΐ«φ‘Ύ“‘Ν§–χΜρΙΧΕ®ΦδΗτ“ΤΕ·≥Λ ΐΨίΩι ±±μœ÷ΝΦΚΟΓΘΙΧΕ®ΦδΗτ¥Ϊ δΒΡ“ΜΗω Ψάΐ « DMA “ΐ«φΖΟΈ ―”≥ΌœΏΒΡΟΩΥΡΗω ΐΨί―υ±ΨΓΘ
Β±ΖΟΈ ≤ΜΝ§–χΜρ“‘ΙΧΕ®ΦδΗτΫχ–– ±Θ§Βδ–ΆΒΡ DMA –‘Ρή≤Δ≤Μ «ΒΡΓΘΒ±¥ΪΆ≥ΒΡ DMA “ΐ«φ“ΤΕ·―≠ΜΖΜΚ≥ε«χ ΐΨί“‘…ζ≥… ΐΉ÷“τΤΒ–ßΙϊ ±Θ§CPU ‘Ύ¥Πάμ“ΜΗω ΐΨίΩι ±±Ί–κΗ…‘Λ÷Ν…ΌΝΫ¥ΈΕ‘ DMA ≤Έ ΐΫχ––±ύ≥ΧΓΘΒ± ΐΨίΖΟΈ ΜΖ»ΤΜΖ–ΈΜΚ≥ε«χ±ΏΫγ ±Θ§CPU –η“ΣΕ‘ DMA ≤Έ ΐΫχ––±ύ≥ΧΘ§≤ΔΗ…‘ΛΙήάμ―”≥ΌœΏΓΘ
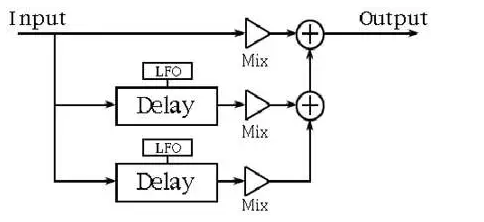
ΆΦ3. Κœ≥ΣΩρΆΦ
Κœ≥Σ–ßΙϊ «ΥΒΟς’β“ΜΒψΒΡ“ΜΗωΦρΒΞΥψΖ® ΨάΐΘ§»γ…œΆΦ 3 Υυ ΨΓΘΚœ≥Σ–ßΙϊΆ®≥Θ”Ο”ΎΗΡ±δά÷ΤςΒΡ…υ“τΘ§ ΙΤδΧΐΤπά¥œώ «ΕύΗωά÷Τς‘Ύ―ίΉύΘ§»γΙϊά÷Τς÷–”–»Υ…υΘ§Ρ«Ο¥¥Υ–ßΙϊΆυΆυΜα ΙΒΞΗω…υ“τΧΐΤπά¥œώΚœ≥ΣΆ≈ΓΘΈ“Ο«Η–÷ΣΕύΗω…υ“τΜρά÷ΤςΘ§“ρΈΣΒ±ΕύΗω…υ“τΜρά÷ΤςΆ§ ±―ίΉύ ±Θ§Ήή «¥φ‘Ύ≤ΜΒΡΆ§≤ΫΚΆ«αΈΔΒΡ“τΗΏ±δΜ·ΓΘ’β–© «Κœ≥Σ–ßΙϊΒΡ÷ς“ΣΧΊ’ςΓΘ
‘ΎΆΦ 3 ÷–Θ§Chorus œ‘ ΨΈΣ δ»κ”κΤδΝΫΗω―”≥ΌΗ±±ΨΒΡΉιΚœΓΘ“τΒςΤΪ≤ν «Ά®Ιΐ―”≥Ό δ»κΗ±±Ψ÷–ΜΚ¬ΐ±δΜ·ΒΡ―”≥ΌΝΩά¥Ϋ®ΡΘΒΡΓΘ―”≥ΌΜΚ¬ΐ±δΜ·Θ§ΤΪ≤νΝΩΦΑΤδΤΒ¬ ”…ΒΆΤΒ’ώΒ¥Τς (LFO) ΩΊ÷ΤΓΘ
»γœ¬ΆΦ4÷–ΒΡChorus Βœ÷ΆΦΥυ ΨΘ§―”≥ΌœΏ «Ά®Ιΐ Ι”ΟΜΖ–ΈΜΚ≥ε«χΘ®”…ΝΫΗωΆ§–Ρ‘≤±μ ΨΘ©ά¥ Βœ÷ΒΡΓΘΆΦ 4 ÷–≥ œ÷ΒΡΚœ≥Σ Βœ÷“βΈΕΉ≈ Ι”ΟΩι¥ΠάμΓΘ¥ΥΚœ≥Σ Ψάΐ÷–ΒΡΩι¥σ–Γ «ΥΡΗω―υ±ΨΓΘ¥Ϊ»κΒΡ―υ±ΨΑ¥Υ≥ ±’κΖΫœρ¥φ¥ΔΒΫ―≠ΜΖΜΚ≥ε«χ÷–ΓΘ
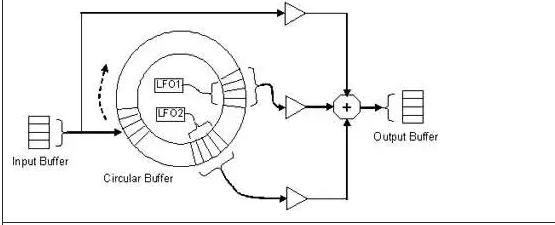
ΆΦ4. Chorus Βœ÷ΩρΆΦ
Ωι¥ΠάμΆ§ ±Ιήάμ ΐΨίΩιΘ®ΕύΗω―υ±ΨΘ©Θ§Εχ≤Μ «÷ΜΙήάμ“ΜΗω―υ±ΨΓΘ‘Ύ¥Υ Ψάΐ÷–Θ§CPU Β»¥ΐΥΡΗω δ»κ―υ±ΨΩ…”ΟΘ§»ΜΚσΦΤΥψΥΡΗω δ≥ω―υ±ΨΓΘΥϋΆ®ΙΐΫΪ δ»κ―υ±ΨΩι”κ¥”―≠ΜΖΜΚ≥ε«χΜώ»ΓΒΡΝΫΗω―”≥Ό ΐΨίΩιœύΫαΚœά¥¥Πάμ’β–©―υ±ΨΓΘ
‘Ύ Ι”Ο¥ΪΆ≥ DMA ΩΊ÷ΤΤςΒΡ«ιΩωœ¬Θ®»γœ¬ΆΦ 5Θ©Θ§ΟΩ¥Έ δ»κ ΐΨίΩιΉΦ±ΗΨΆ–ς ±Θ§CPU ΕΦΜα ’ΒΫ÷–ΕœΆ®÷ΣΓΘ»ΜΚσCPUΦΤΥψΚœ≥Σ δ≥ωΓΘ
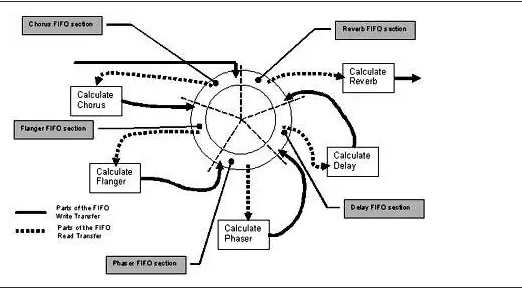
ΆΦ5. ≤…”Ο¥ΪΆ≥ DMA ± Chorus Βœ÷ ±Φδ±μ
±Ψάΐ÷–ΒΡ DMA “ΐ«φΖ÷≈δ±Ί–κ÷¥––ΝΫΗωΙΊΦϋ≤ΌΉςΘΚ
1) ΫΪ“ΜΩι δ»κ―υ±Ψ¥φ¥ΔΒΫ―≠ΜΖΜΚ≥ε«χΘ®“‘Ι©ΫΪά¥≤ΈΩΦΘ©2) ¥”―≠ΜΖΜΚ≥ε«χΦλΥςΝΫΩι―”≥Ό ΐΨίΘ®ΈΣœ¬“ΜΗω δ»κ―υ±ΨΩιΉΦ±Η―”≥Ό ΐΨίΘ©ΓΘ
‘Ύ’β÷÷«ιΩωœ¬Θ§CPU ±Ί–κΆ®ΙΐΗζΉΌΚΆ±ύ≥Χ‘¥ΒΊ÷ΖΚΆΡΩ±ξΒΊ÷Ζά¥–≠÷ζ DMAΘ§≤Δ‘Ύ ΐΨίΖΟΈ »ΤΙΐΜΚ≥ε«χ±ΏΫγ ±Ϋχ––Η…‘ΛΓΘ’β–η“Σ‘ΎΟΩ¥Έ¥Ϊ δ÷°«Α≈δ÷Ο DMA “ΐ«φΓΘ
‘Ύ CPU ÷Ί–¬≈δ÷Ο DMA ÷°«ΑΘ§ΟΩΗωΤΪ“ΤΝΩ±Ί–κ”… CPU ΦΤΥψΘ®Μρ¥”‘Λœ»ΦΤΥψΒΡ±μ÷–Μώ»ΓΘ©ΓΘCPU ¥χΩμΒΟΒΫάϊ”ΟΘ§“ρΈΣΥϋ±Ί–κ‘ΎΟΩ¥Έ¥Ϊ δ÷°«Α÷Ί–¬≈δ÷Ο DMA “ΐ«φΓΘ‘ΎΆΦ 5 ÷–Θ§CPU ±ΦδœΏΜνΕ·œ‘ ΨΈΣΝΫ––ΘΚ––œ‘ ΨΝΥ¥ΠάμΚœ≥Σ–ßΙϊΥυ–ηΒΡ CPU ΜνΕ·Θ§ΒΎΕΰ––œ‘ ΨΝΥ≈δ÷Ο DMA Υυ–ηΒΡ CPU ΜνΕ·ΓΘ
‘ΎΗ¥‘”ΒΡ ΐΉ÷“τΤΒ–ßΙϊΘ®άΐ»γΜλœλΘ©ΒΡ«ιΩωœ¬Θ§±Ί–κ¥”―≠ΜΖΜΚ≥εΤς÷–ΦλΥςΒΡ―”≥ΌΩιΒΡ ΐΝΩΩ…“‘¥οΒΫ256ΜρΗϋΕύΓΘ¥ΥΆβΘ§’β–©―”≥ΌΩι÷–ΒΡΟΩ“ΜΗωΕΦ≤Μ «ΙΧΕ®ΦδΗτΒΡΘ§≤Δ«“ΥφΉ≈ΥψΖ®‘Υ––Θ§ΤΪ“ΤΝΩ≤ΜΕœ±δΜ·ΓΘΥφΉ≈―≠ΜΖΜΚ≥ε«χ÷– ΐΨίΖΟΈ ΝΩΒΡΦ±Ψγ‘ωΦ”Θ§ΗϋΗ¥‘”ΒΡ ΐΉ÷“τΤΒ–ßΙϊΥψΖ®Θ®»γΜλœλΘ©ΫΪ–η“ΣΗϋΕύΒΡ CPU ÷ήΤΎΓΘ’β ΙΒΟΩ…”Ο”Ύ ΒΦ ”Π”Ο≥Χ–ρΒΡ CPU ¥χΩμΦθ…ΌΓΘ
Β±ΕύΗω ΐΉ÷“τΤΒ–ßΙϊœύΦΧ≥ωœ÷ ±Θ®»γΆΦ 1 Υυ ΨΘ©Θ§CPU ΫΪ±Ί–κ–≠÷ζ DMA “ΤΕ·ΟΩΗω¥ΠάμΫΉΕΈΥυ–ηΚΆ≤ζ…ζΒΡ ΐΨίΓΘ‘Ύ’β–©»ΈΈώΤΎΦδΘ§CPU ΚΆ DMA ±Ί–κΆ§≤ΫΓΘΆ§≤Ϋ”… DMA ¥ΌΫχΘ§ΥϋΜα÷–Εœ CPUΓΘ
“ρ¥ΥΘ§œΒΆ≥÷–ΒΡ÷–Εœ ΐΝΩΜαΥφΉ≈œΒΆ≥Η¥‘”Ε»ΒΡ‘ωΦ”Εχ‘ωΦ”ΓΘ’β–©÷–ΕœΜα¥χά¥ΚήΗΏΒΡΩΣœζΘ§“ρΈΣ±Ί–κ±Θ¥φΦΡ¥φΤς“‘±ΘΝτ…œœ¬ΈΡΓΘ≥ΐ¥Υ÷°ΆβΘ§÷–ΕœΜΙΜαΨ≠Ιΐ¥ΠάμΙήΒά≤ΔΤΤΜΒ÷ΗΝνΜΚ¥φΒΡΈΔΟν–߬ ΓΘ±ΘΝτ…œœ¬ΈΡΜαœϊΚΡ¥σΝΩ÷ήΤΎΘ§≤ΔΫχ“Μ≤ΫΗΡ±δ÷ΗΝνΜΚ¥φΒΡ–‘ΡήΓΘΙήΒάΒΡΙΐΕ»÷–Εœ“≤÷±Ϋ””Αœλ’ϊΧε–‘ΡήΓΘ
|

