|
’Σ“Σ
”–œό¬ω≥εœλ”Π(FIR)ΚΆΈόœό¬ω≥εœλ”Π(IIR)¬Υ≤®ΤςΕΦ «≥Θ”ΟΒΡ ΐΉ÷–≈Κ≈¥ΠάμΥψΖ®---”»Τδ ”Ο”Ύ“τΤΒ¥Πάμ”Π”ΟΓΘ“ρ¥ΥΘ§‘ΎΒδ–ΆΒΡ“τΤΒœΒΆ≥÷–Θ§¥ΠάμΤςΡΎΚΥΒΡΚή¥σ“Μ≤ΩΖ÷ ±Φδ”Ο”ΎFIRΚΆIIR¬Υ≤®ΓΘ ΐΉ÷–≈Κ≈¥ΠάμΤς…œΒΡΤ§ΡΎFIRΚΆIIR”≤ΦΰΦ”ΥΌΤς“≤Ζ÷±π≥ΤΈΣFIRAΚΆIIRAΘ§Έ“Ο«Ω…“‘άϊ”Ο’β–©”≤ΦΰΦ”ΥΌΤςά¥Ζ÷ΒΘFIRΚΆIIR¥Πάμ»ΈΈώΘ§»ΟΡΎΚΥ»Ξ÷¥––ΤδΥϊ¥Πάμ»ΈΈώΓΘ‘Ύ±ΨΈΡ÷–Θ§Έ“Ο«ΫΪΫη÷ζ≤ΜΆ§ΒΡ Ι”ΟΡΘ–Ά“‘ΦΑ Β ±≤β ‘ Ψάΐά¥ΧΫΧ÷»γΚΈ‘Ύ ΒΦυ÷–άϊ”Ο’β–©Φ”ΥΌΤςΓΘ
ΦρΫι

ΆΦ1.FIRAΚΆIIRAœΒΆ≥ΖΫΩρΆΦ
ΆΦ1œ‘ ΨΝΥFIRAΚΆIIRAΒΡΦρΜ·ΖΫΩρΆΦΘ§“‘ΦΑΥϋΟ«”κΤδ”ύ¥ΠάμΤςœΒΆ≥ΚΆΉ ‘¥ΒΡΫΜΜΞΖΫ ΫΓΘ
ΓΛ FIRAΚΆIIRAΡΘΩιΨυ÷ς“ΣΑϋΚ§“ΜΗωΦΤΥψ“ΐ«φΘ®≥ΥάέΦ”(MAC)ΒΞ‘ΣΘ©“‘ΦΑ“ΜΗω–ΓΒΡ±ΨΒΊ ΐΨίΚΆœΒ ΐRAMΓΘ
ΓΛ u ΈΣΩΣ ΦΫχ––FIRA/IIRA¥ΠάμΘ§ΡΎΚΥ Ι”ΟΆ®ΒάΧΊΕ®–≈œΔ≥θ ΦΜ·¥ΠάμΤς¥φ¥ΔΤς÷–ΒΡDMA¥Ϊ δΩΊ÷ΤΩι(TCB)Ν¥ΓΘ»ΜΚσΫΪΗΟTCBΝ¥ΒΡΤπ ΦΒΊ÷Ζ–¥»κFIRA/IIRAΝ¥÷Η’κΦΡ¥φΤςΘ§ΥφΚσ≈δ÷ΟFIRA/IIRAΩΊ÷ΤΦΡ¥φΤς“‘ΤτΕ·Φ”ΥΌΤς¥ΠάμΓΘ“ΜΒ©Υυ”–Ά®ΒάΒΡ≈δ÷ΟΆξ≥…Θ§ΨΆΜαœρΡΎΚΥΖΔΥΆ“ΜΗω÷–ΕœΘ§“‘±ψΡΎΚΥΫΪ¥ΠάμΚσΒΡ δ≥ω”Ο”ΎΚσ–χ≤ΌΉςΓΘ
ΓΛ u ¥”άμ¬έ…œΫ≤Θ§ΉνΚΟΒΡΖΫΖ® «ΫΪΥυ”–FIRΚΆ/ΜρIIR»ΈΈώ¥”ΡΎΚΥΉΣ“ΤΗχΦ”ΥΌΤςΘ§≤Δ‘ –μΡΎΚΥΆ§ ±÷¥––ΤδΥϊ≤ΌΉςΓΘΒΪ‘Ύ ΒΦυ÷–Θ§’β≤ΔΖ« Φ÷’Ω…––Θ§ΧΊ±π «Β±ΡΎΚΥ–η“Σ Ι”ΟΦ”ΥΌΤς δ≥ωΫχ“Μ≤Ϋ¥ΠάμΘ§≤Δ«“ΟΜ”–ΤδΥϊΕάΝΔΒΡ»ΈΈώ–η“ΣΆ§ ±Άξ≥… ±ΓΘ‘Ύ’β÷÷«ιΩωœ¬Θ§Έ“Ο«–η“Σ―Γ‘ώΚœ ΒΡΦ”ΥΌΤς Ι”ΟΡΘ–Άά¥¥οΒΫΉνΦ―–ßΙϊΓΘ.
‘Ύ±ΨΈΡ÷–Θ§Έ“Ο«ΫΪΧ÷¬έ’κΕ‘≤ΜΆ§”Π”Ο≥ΓΨΑ≥δΖ÷άϊ”Ο’β–©Φ”ΥΌΤςΒΡΗς÷÷ΡΘ–ΆΓΘ
Β ± Ι”ΟFIRAΚΆIIRA
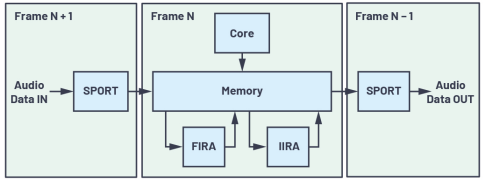
ΆΦ2.Βδ–Ά Β ±“τΤΒ ΐΨίΝς
ΆΦ2œ‘ ΨΝΥΒδ–Ά Β ±PCM“τΤΒ ΐΨίΝςΆΦΓΘ“Μ÷Γ ΐΉ÷Μ·PCM“τΤΒ ΐΨίΆ®ΙΐΆ§≤Ϋ¥°––ΕΥΩΎ(SPORT)Ϋ” ’Θ§≤ΔΆ®Ιΐ÷±Ϋ”¥φ¥ΔΤςΖΟΈ (DMA)ΖΔΥΆ÷Ν¥φ¥ΔΤςΓΘ‘ΎΦΧ–χΫ” ’÷ΓN+1 ±Θ§÷ΓN”…ΡΎΚΥΚΆ/ΜρΦ”ΥΌΤς¥ΠάμΘ§÷°«Α¥ΠάμΒΡ÷Γ(N-1)ΒΡ δ≥ωΆ®ΙΐSPORTΖΔΥΆ÷ΝDACΫχ–– ΐΡΘΉΣΜΜΓΘ
Φ”ΥΌΤς Ι”ΟΡΘ–Ά
»γ«ΑΥυ ωΘ§ΗυΨί”Π”ΟΒΡ≤ΜΆ§Θ§Ω…Ρή–η“Σ“‘≤ΜΆ§ΒΡΖΫ Ϋ Ι”ΟΦ”ΥΌΤςΘ§“‘Ήν¥σœόΕ»Ζ÷ΒΘFIRΚΆ/ΜρIIR¥Πάμ»ΈΈώΘ§≤ΔΨΓΩ…ΡήΫΎ ΓΡΎΚΥ÷ήΤΎ“‘”Ο”ΎΤδΥϊ≤ΌΉςΓΘ¥”ΗΏ≤ψ¥ΈΫ«Ε»ά¥Ω¥Θ§Φ”ΥΌΤς Ι”ΟΡΘ–ΆΩ…Ζ÷ΈΣ»ΐάύΘΚ÷±Ϋ”Χφ¥ζΓΔ≤πΖ÷»ΈΈώΚΆ ΐΨίΝςΥ°œΏΓΘ
÷±Ϋ”Χφ¥ζ
ΓΛ ΡΎΚΥFIRΚΆ/ΜρIIR¥Πάμ÷±Ϋ”±ΜΦ”ΥΌΤςΧφ¥ζΘ§ΡΎΚΥ÷Μ–ηΒ»¥ΐΦ”ΥΌΤςΆξ≥…¥Υ»ΈΈώΓΘ
ΓΛ ¥ΥΡΘ–ΆΫω‘ΎΦ”ΥΌΤςΒΡ¥ΠάμΥΌΕ»±»ΡΎΚΥΩλ ±≤≈”––ßΘΜΦ¥Θ§ Ι”ΟFIRAΡΘΩιΓΘ
≤πΖ÷»ΈΈώ
ΓΛ FIRΚΆ/ΜρIIR¥Πάμ»ΈΈώ‘ΎΡΎΚΥΚΆΦ”ΥΌΤς÷°ΦδΖ÷≈δΓΘ
ΓΛ Β±ΕύΗωΆ®ΒάΩ…≤Δ––¥Πάμ ±Θ§¥ΥΡΘ–ΆΧΊ±π”–”ΟΓΘ
ΓΛ ΗυΨί¥÷¬‘ΒΡ ±–ρΙάΥψΘ§‘ΎΡΎΚΥΚΆΦ”ΥΌΤς÷°ΦδΖ÷≈δΆ®ΒάΉή ΐΘ§ ΙΕΰ’Ώ¥σ÷¬ΡήΙΜΆ§ ±Άξ≥…»ΈΈώΓΘ
ΓΛ »γΆΦ3Υυ ΨΘ§”κ÷±Ϋ”Χφ¥ζΡΘ–Άœύ±»Θ§¥Υ Ι”ΟΡΘ–ΆΩ…ΫΎ ΓΗϋΕύΒΡΡΎΚΥ÷ήΤΎΓΘ
ΐΨίΝςΥ°œΏ
ΓΛ ΡΎΚΥΚΆΦ”ΥΌΤς÷°ΦδΒΡ ΐΨίΝςΩ…Ϋχ––ΝςΥ°œΏ¥ΠάμΘ§ ΙΕΰ’ΏΡήΙΜ‘Ύ≤ΜΆ§ ΐΨί÷Γ…œ≤Δ––¥ΠάμΓΘ
ΓΛ u »γΆΦ3Υυ ΨΘ§ΡΎΚΥ¥ΠάμΒΎNΗω÷ΓΘ§»ΜΚσΤτΕ·Φ”ΥΌΤςΕ‘ΗΟ÷ΓΫχ––¥ΠάμΓΘΡΎΚΥΥφΚσΦΧ–χΫχ“Μ≤Ϋ≤Δ––¥ΠάμΦ”ΥΌΤς‘Ύ…œ“ΜΒϋ¥ζ÷–≤ζ…ζΒΡΒΎN-1÷ΓΒΡ δ≥ωΓΘΗΟ–ρΝ–‘ –μΫΪFIRΚΆ/ΜρIIR¥Πάμ»ΈΈώΆξ»ΪΉΣ“ΤΗχΦ”ΥΌΤςΘ§ΒΪ δ≥ωΜα”–“Μ–©―”≥ΌΓΘ
ΓΛ u ΝςΥ°œΏΦΕ“‘ΦΑ δ≥ω―”≥ΌΕΦΩ…ΡήΜα‘ωΦ”Θ§ΨΏΧε»ΓΨω”ΎΆξ’ϊ¥ΠάμΝ¥÷–¥ΥάύFIRΚΆ/ΜρIIR¥ΠάμΦΕΒΡ ΐΝΩΓΘ
ΆΦ3ΥΒΟςΝΥ“τΤΒ ΐΨί÷Γ»γΚΈ‘Ύ≤ΜΆ§Φ”ΥΌΤς Ι”ΟΡΘ–ΆΒΡ»ΐΗωΫΉΕΈ÷°Φδ¥Ϊ δ---DMA INΓΔΡΎΚΥ/Φ”ΥΌΤς¥ΠάμΚΆDMA OUTΓΘΥϋΜΙœ‘ ΨΝΥΆ®Ιΐ≤…”Ο≤ΜΆ§ΒΡΦ”ΥΌΤς Ι”ΟΡΘ–ΆΫΪFIR/IIR»Ϊ≤ΩΜρ≤ΩΖ÷¥ΠάμΉΣ“ΤΒΫΦ”ΥΌΤς…œΘ§”κΫω Ι”ΟΡΎΚΥΡΘ–Άœύ±»Θ§ΡΎΚΥΩ’œ–÷ήΤΎ»γΚΈ‘ωΦ”ΓΘ
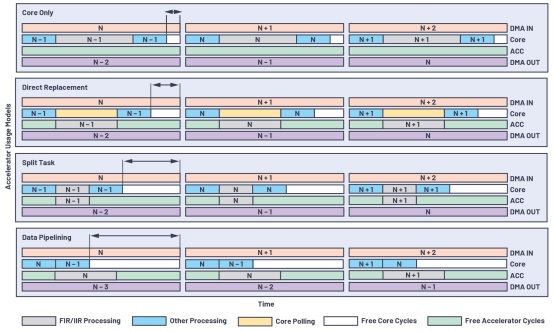
ΆΦ3.Φ”ΥΌΤς Ι”ΟΡΘ–Ά±»Ϋœ
SHARC¥ΠάμΤς…œΒΡFIRAΚΆIIRA
“‘œ¬ADI SHARC®¥ΠάμΤςœΒΝ–÷ß≥÷Τ§ΡΎFIRAΚΆIIRAΘ®¥”Ψ…ΒΫ–¬Θ©ΓΘ
ΓΛ ADSP-214xx (άΐ»γΘ§ ADSP-21489)
ΓΛ ADSP-SC58x
ΓΛ ADSP-SC57x/ADSP-2157x
ΓΛ ADSP-2156x
’β–©¥ΠάμΤςœΒΝ–ΘΚ
ΓΛ ΦΤΥψΥΌΕ»≤ΜΆ§
ΓΛ Μυ±Ψ±ύ≥ΧΡΘ–Ά±Θ≥÷≤Μ±δΘ§ADSP-2156x¥ΠάμΤς…œΒΡΉ‘Ε·≈δ÷ΟΡΘ Ϋ(ACM)≥ΐΆβΓΘ
ΓΛ FIRA”–ΥΡΗωMACΒΞ‘ΣΘ§ΕχIIRA÷Μ”–“ΜΗωMACΒΞ‘ΣΓΘ
ADSP-2156x¥ΠάμΤς…œΒΡFIRA/IIRAΗΡΫχ
ADSP-2156x «SHARC¥ΠάμΤςœΒΝ–÷–ΒΡΉν–¬ΒΡ≤ζΤΖΓΘΥϋ «ΒΎ“ΜΩνΒΞΚΥ1 GHz SHARC¥ΠάμΤςΘ§ΤδFIRAΚΆIIRA“≤Ω…‘Ύ1 GHzœ¬‘Υ––ΓΘADSP-2156x¥ΠάμΤς…œΒΡFIRAΚΆIIRA”κΤδ«Α¥ζADSP-SC58x/ADSP-SC57x¥ΠάμΤςœύ±»Θ§ΨΏ”–ΕύœνΗΡΫχΓΘ
–‘ΡήΗΡΫχ
ΓΛ ΦΤΥψΥΌΕ»ΧαΗΏΝΥ8±ΕΘ®¥”SCLK-125 MHz÷ΝCCLK-1 GHzΘ©ΓΘ
ΓΛ ”…”ΎΡΎΚΥΚΆΦ”ΥΌΤςΫη÷ζΉ®”ΟΡΎΚΥΫαΙΙ Βœ÷ΝΥΗϋΫτΟήΒΡΦ·≥…Θ§“ρ¥ΥΦθ…ΌΝΥΡΎΚΥΚΆΦ”ΥΌΤς÷°ΦδΒΡ ΐΨίΚΆMMRΖΟΈ ―”≥ΌΓΘ
ΙΠΡήΗΡΫχ
ΧμΦ”ΝΥACM÷ß≥÷Θ§“‘ΨΓΝΩΦθ…ΌΫχ––Φ”ΥΌΤς¥ΠάμΥυ–ηΒΡΡΎΚΥΗ…‘ΛΓΘ¥ΥΡΘ Ϋ÷ς“ΣΨΏ”–“‘œ¬–¬ΧΊ–‘ΘΚ
ΓΛ ‘ –μΦ”ΥΌΤς‘ίΆΘ“‘Ϋχ––Ε·Χ§»ΈΈώ≈≈Ε”ΓΘ
ΓΛ ΈόΆ®Βά ΐœό÷ΤΓΘ
ΓΛ ÷ß≥÷¥ΞΖΔ…ζ≥…Θ®÷ςΤςΦΰΘ©ΚΆ¥ΞΖΔΒ»¥ΐΘ®¥”ΤςΦΰΘ©ΓΘ
ΓΛ ΈΣΟΩΗωΆ®Βά…ζ≥…―Γ‘ώ–‘÷–ΕœΓΘ
Β―ιΫαΙϊ
‘Ύ±ΨΫΎ÷–Θ§Έ“Ο«ΫΪΧ÷¬έ‘ΎADSP-2156xΤάΙάΑε…œΘ§Ϋη÷ζ≤ΜΆ§ΒΡΦ”ΥΌΤς Ι”ΟΡΘ–Ά Β ©ΝΫΗω Β ±ΕύΆ®ΒάFIR/IIR”ΟάΐΒΡΫαΙϊ
”Οάΐ1
ΆΦ4œ‘ Ψ”Οάΐ1ΒΡΖΫΩρΆΦΓΘ≤…―υ¬ ΈΣ48 kHzΘ§ΡΘΩι¥σ–ΓΈΣ256Ηω≤…―υΒψΘ§≤πΖ÷»ΈΈώΡΘ–Ά÷– Ι”ΟΒΡΡΎΚΥ”κΦ”ΥΌΤςΆ®Βά±»ΈΣ5:7ΓΘ
±μ1œ‘ Ψ≤βΒΟΒΡΡΎΚΥΚΆFIRA MIPS ΐΝΩΘ§“‘ΦΑ”κΫω Ι”ΟΡΎΚΥΡΘ–Άœύ±»ΜώΒΟΒΡΫΎ‘ΦΡΎΚΥMIPSΫαΙϊΓΘ±μ÷–ΜΙœ‘ ΨΝΥœύ”Π Ι”ΟΡΘ–Ά‘ωΦ”ΒΡΕνΆβ δ≥ω―”≥ΌΓΘ’ΐ»γΈ“Ο«ΥυΩ¥ΒΫΒΡΘ§ Ι”ΟΦ”ΥΌΤς≈δΚœ ΐΨίΝςΥ°œΏ Ι”ΟΡΘ–ΆΘ§Ω…ΫΎ‘ΦΗΏ¥ο335ΡΎΚΥMIPSΘ§ΒΪΒΦ÷¬1Ωι(5.33 ms)ΒΡ δ≥ω―”≥ΌΓΘ÷±Ϋ”Χφ¥ζΚΆ≤πΖ÷»ΈΈώ Ι”ΟΡΘ–Ά“≤Ζ÷±πΩ…ΫΎ‘Φ98 MIPSΚΆ189 MIPSΘ§Εχ«“Έ¥ΒΦ÷¬»ΈΚΈΕνΆβΒΡ δ≥ω―”≥ΌΓΘ
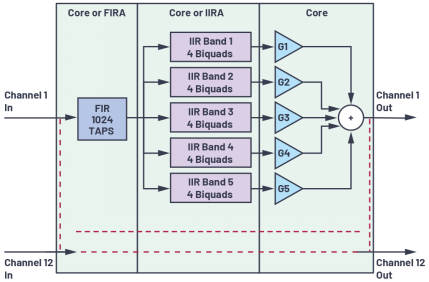
ΆΦ4.”Οάΐ1ΖΫΩρΆΦ
|
±μ1.”Οάΐ1ΒΡΡΎΚΥΚΆFIR/IIRA MIPSΉήΫα
|
|
Ι”ΟΡΘ–Ά
|
ΡΎΚΥ MIPS
|
FIRA MIPS
|
IIRA MIPS
|
ΫΎ‘ΦΡΎΚΥMIPS
|
Ι”ΟΡΘ–Ά―”≥Ό(ms)
|
|
Ϋω Ι”ΟΡΎΚΥ
|
337
|
|
|
|
0
|
|
÷±Ϋ”Χφ¥ζ
|
239
|
162
|
75
|
98
|
0
|
|
≤πΖ÷»ΈΈώ
|
148
|
96
|
44
|
189
|
0
|
|
ΐΨίΝςΥ°œΏ
|
2
|
161
|
75
|
335
|
5.33 (1÷Γ)
|
”Οάΐ2
ΆΦ5œ‘ Ψ”Οάΐ2ΒΡΖΫΩρΆΦΓΘ≤…―υ¬ ΈΣ48 kHzΘ§ΡΘΩι¥σ–ΓΈΣ128Ηω≤…―υΒψΘ§≤πΖ÷»ΈΈώΡΘ–Ά÷– Ι”ΟΒΡΡΎΚΥ”κΦ”ΥΌΤςΆ®Βά±»ΈΣ1:1ΓΘ
”κ±μ1“Μ―υΘ§±μ2“≤œ‘ ΨΝΥ¥Υ”ΟάΐΒΡΫαΙϊΓΘ’ΐ»γΈ“Ο«ΥυΩ¥ΒΫΒΡΘ§ Ι”ΟΦ”ΥΌΤς≈δΚœ ΐΨίΝςΥ°œΏ Ι”ΟΡΘ–ΆΘ§Ω…ΫΎ‘ΦΗΏ¥ο490ΡΎΚΥMIPSΘ§ΒΪΒΦ÷¬1ΡΘΩι(2.67 ms)ΒΡ δ≥ω―”≥ΌΓΘ≤πΖ÷»ΈΈώ Ι”ΟΡΘ–ΆΩ…ΫΎ‘Φ234ΡΎΚΥMIPSΘ§ΕχΟΜ”–ΒΦ÷¬»ΈΚΈΕνΆβ δ≥ω―”≥ΌΓΘ«κΉΔ“βΘ§”κ”Οάΐ1÷–≤ΜΆ§Θ§‘Ύ”Οάΐ2÷–ΡΎΚΥ Ι”ΟΤΒ”ρΘ®ΩλΥΌΨμΜΐΘ©¥ΠάμΘ§ΕχΖ« ±”ρ¥ΠάμΓΘ’βΨΆ «ΈΣΚΈ¥Πάμ“ΜΗωΆ®ΒάΥυ–ηΒΡΡΎΚΥMIPS±»FIRA MIPS…ΌΒΡ‘≠“ρΘ§’βΩ…ΒΦ÷¬÷±Ϋ”Χφ¥ζ Ι”ΟΡΘ–Ά Βœ÷ΗΚΒΡΡΎΚΥMIPSΫΎ‘ΦΓΘ
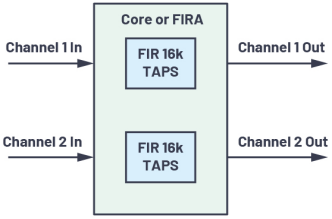
ΆΦ5.”Οάΐ2ΖΫΩρΆΦ
|
±μ2.”Οάΐ2ΒΡΡΎΚΥΚΆFIR/IIRA MIPSΉήΫα
|
|
Ι”ΟΡΘ–Ά
|
ΡΎΚΥMIPS
|
FIRA MIPS
|
ΫΎ‘ΦΡΎΚΥMIPS
|
Ι”ΟΡΘ–Ά―”≥Ό(ms)
|
|
Ϋω Ι”ΟΡΎΚΥ
|
493
|
|
|
0
|
|
÷±Ϋ”Χφ¥ζ
|
515
|
511
|
®C22
|
0
|
|
≤πΖ÷»ΈΈώ
|
259
|
257
|
234
|
0
|
|
ΐΨίΝςΥ°œΏ
|
3
|
511
|
490
|
2.67 (1÷Γ)
|
Ϋα¬έ
‘Ύ±ΨΈΡ÷–Θ§Έ“Ο«Ω¥ΒΫ»γΚΈάϊ”Ο≤ΜΆ§ΒΡΦ”ΥΌΤς Ι”ΟΡΘ–Ά Βœ÷Υυ–ηΒΡMIPSΚΆ¥ΠάμΡΩ±ξΘ§¥”ΕχΫΪ¥σΝΩΡΎΚΥMIPSΉΣ“ΤΒΫADSP-2156x¥ΠάμΤς…œΒΡFIRAΚΆIIRAΦ”ΥΌΤςΓΘ
|

